
MoE 论文研读
前两篇基础且经典的 MoE 工作可见:
Adaptive Mixtures of Local Experts 论文研读 | Relativity suis’s Blog
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Model
Sparse scaling of the Transformer architecture
首先简单回顾 Transformer 结构:
Transformer 编码器层由两个连续的层组成,即自注意力层和逐位置前馈层。解码器在此基础上增加了第三个交叉注意力层,该层会对编码器的输出进行关注。
作者通过条件计算对 Transformer 进行稀疏扩展,具体方法是在编码器和解码器中每隔一个前馈层替换为一个逐位置专家混合(MoE)层,并使用一种 top-2 门控的变体(如下图所示)。我们通过调整 Transformer 层的数量以及每个 MoE 层中专家的数量来扩展模型的容量。
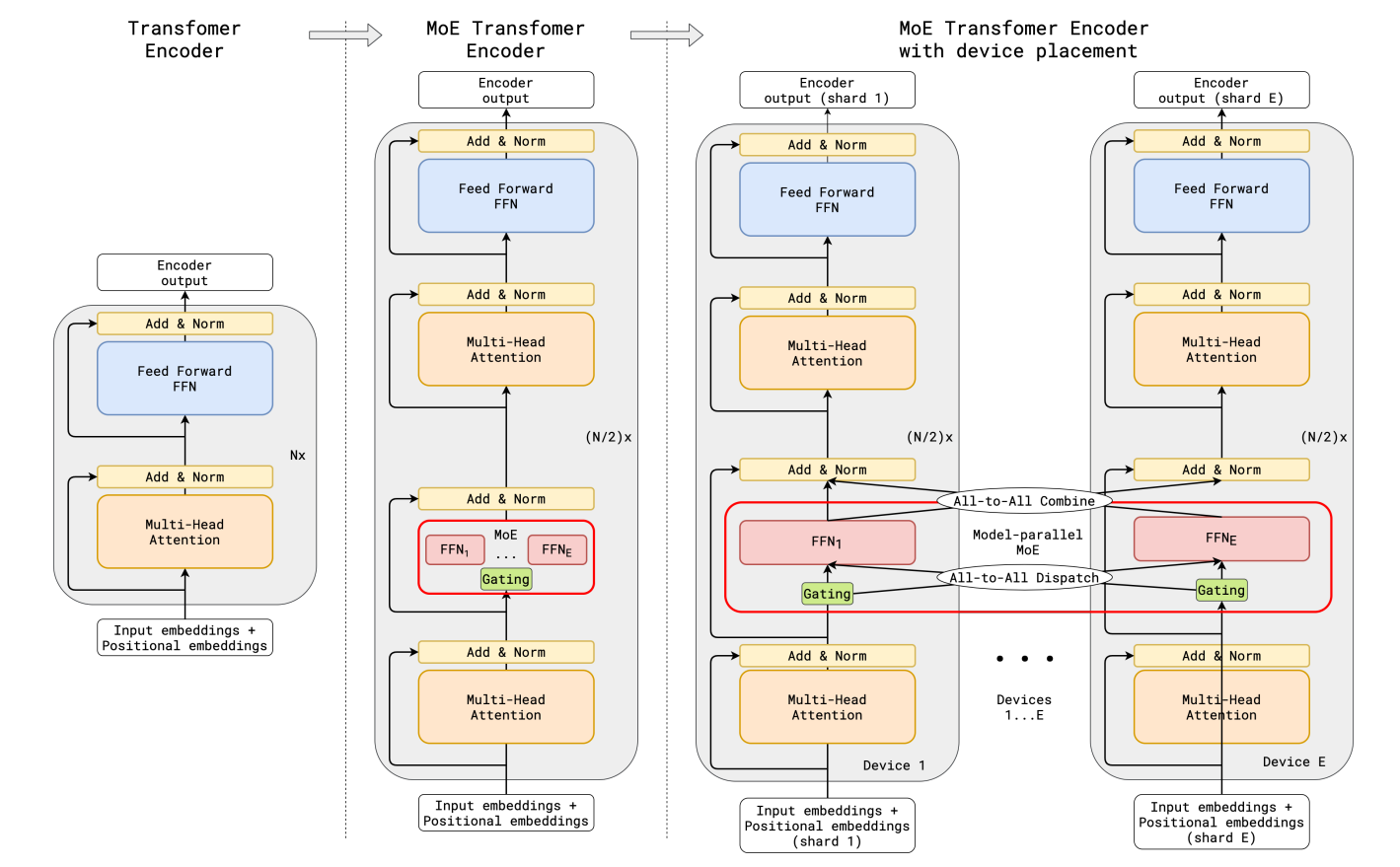
图片展示了使用 MoE 层扩展 Transformer 编码器的示意图,MoE 层替换了每隔一个的 Transformer 前馈层,解码器的修改方式类似。(a) 标准 Transformer 模型的编码器是由自注意力层和前馈层交替堆叠而成,中间穿插残差连接和层归一化。(b) 通过每隔一个前馈层替换为 MoE 层,我们得到了 MoE Transformer 编码器的模型结构。(c) 当扩展到多设备时,MoE 层会在设备间分片,而其他所有层则会被复制。
Position-wise Mixture-of-Experts Layer
模型中使用的 MoE 层是基于 Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer 这篇工作的,在稀疏门控函数和辅助损失函数上有所变化,在该模型中的 MoE 层由 $E$ 个前馈网络 $FFN{1} \cdots FFN{E}$ 组成:
其中 $x{s}$ 是 MoE 层的输入向量,$wi$ 和 $wo$ 分别是前馈层(一个专家)的输入和输出的投影矩阵,向量 $\mathcal{G}{s,E}$ 由一个门控网络计算得出