
LoRA 及其论文研读
参考链接:
https://martinlwx.github.io/zh-cn/lora-finetuning/
https://github.com/huggingface/peft
论文链接:
https://arxiv.org/abs/2106.09685
论文研读:LoRA: Low-Rank Adaptation of Large Language Models
Abstract
An important paradigm of natural language processing consists of large-scale pretraining on general domain data and adaptation to particular tasks or domains. As we pretrain larger models, full fine-tuning, which retrains all model parameters, becomes less feasible. Using GPT-3 175B as an example – deploying independent instances of fine-tuned models, each with 175B parameters, is prohibitively expensive. We propose Low-Rank Adaptation, or LoRA, which freezes the pretrained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks. Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times. LoRA performs on-par or better than fine-tuning in model quality on RoBERTa, DeBERTa, GPT-2, and GPT-3, despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency. We also provide an empirical investigation into rank-deficiency in language model adaptation, which sheds light on the efficacy of LoRA. We release a package that facilitates the integration of LoRA with PyTorch models and provide our implementations and model checkpoints for RoBERTa, DeBERTa, and GPT-2 at https://github.com/microsoft/LoRA.
随着预训练模型越来越大的趋势,对其进行全量的微调(重新调整所有参数)变得越来越不切实际,作者提出 Low-Rank Adaptation, or LoRA,即 低秩适应,它冻结了预训练模型的权重,并向 Transformer 模型的每一层注入一个可训练的秩分解矩阵,大大减少了下游任务中需要训练的参数数量。与使用Adam算法微调的GPT-3 175B相比,LoRA可以将可训练参数数量减少1万倍,GPU内存需求减少3倍。在模型质量上,LoRA的性能与在RoBERTa、DeBERTa、GPT-2和GPT-3上的全面微调相比相当或更好,尽管它的可训练参数更少,训练吞吐量更高,并且与适配器不同,没有额外的推理延迟。
前言与问题
图1
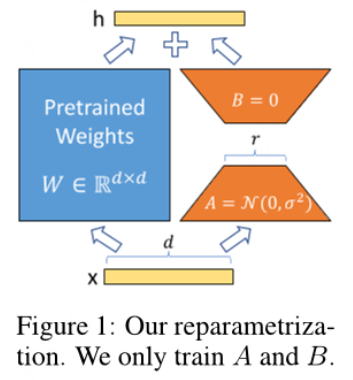
LoRA的几个关键优势:
- 一个预训练模型可以共享并用于构建许多不同的小 LoRA 模块,我们可以冻结共享模型,并通过替换图 1 中的矩阵A和B来有效地切换任务,从而大大降低存储需求和任务切换开销。
- LoRA 通过使用自适应优化器,使训练更高效,并降低了高达三倍的硬件门槛,因为我们不需要计算大多数参数的梯度或维护优化器状态;相反,我们只优化注入的小得多的低秩矩阵。
- 这种简单的线性设计允许我们在部署时合并可训练矩阵和冻结权重,从结构上讲,在推理延迟方面与完全微调模型相比,没有引入任何推理延迟。
- LoRA 与许多先前的方法正交,可以与其中许多方法(如 prefix-tuning)结合使用。
tips:本文主要关注语言建模任务的案例。
全微调(full fine-tuning)的主要缺点之一是,对于每个下游任务,我们都要学习一组不同的参数 $\Delta\Phi$,其维度 $|\Delta\Phi|$ 等于 $|\Phi_0|$。因此,如果预训练模型很大(比如GPT-3的 $|\Phi_0| \approx 175$ Billion),存储和部署许多独立的微调模型实例将变得具有挑战性,甚至可能不可行。在全微调时,模型会从预训练权重 $\Phi_0$ 初始化,并反复根据梯度来更新权重为 $\Phi_0 + \Delta \Phi$ 以最大化条件语言建模的目标:
而在本文中,作者采取了一种更具参数效率(parameter-efficient)的方法,其中任务特定的参数增量 $\Delta \Phi = \Delta \Phi(\Theta)$ 由一个更小的参数集 $\Theta$ 编码,其中 $|\Theta| \ll |\Phi_0|$,因此,寻找 $\Delta \Phi$ 的任务变为优化 $\Theta$:
最大化的参数变成了 $\Theta$,概率函数中的参数变成了 $\Phi_0+\Delta\Phi(\Theta)$,其中:
- $\Phi_0$ 是预训练模型的原始参数;
- $\Delta\Phi(\Theta)$ 表示由参数 $\Theta$ 控制的参数更新量;
这种方法既节省计算资源,也节省内存需求,对于具有175B参数的 GPT-3,参数 $\Theta$ 仅有原来 $|\Phi_0|$ 的 $0.01\%$。
现有方法的不足
- 添加适配器层(Adapter Layers)引入推理延迟
无论是 Houlsby 等人(2019)设计的适配器在每个 Transformer 模块中包含两个适配器层,还是 Lin 等人(2020)的设计则在每个模块中包含一个适配器层但增加了一个 LayerNorm 层,适配器层的增加都会带来额外的计算步骤。尽管适配器通过设置较小的瓶颈维度来限制参数量(有时甚至不到原模型的1%),从FLOPs(每秒浮点运算次数)的角度来看,这些额外的计算量并不显著。
然而大型神经网络依赖于硬件的并行计算能力以保持低延迟,而适配器层必须按顺序处理,这限制了并行计算的效率,尤其是在线推理(batch size 通常为1)的情况下,无法充分利用并行优势,从而导致延迟增加。
此外当需要对模型进行切分(Shard)的时候,适配器的额外深度要求更多的同步GPU操作(如 AllReduce 和 Broadcast),这进一步增加了推理延迟,除非适配器参数被冗余存储多次,这又会带来存储和通信的开销。
- 直接优化 Prompt 很困难
如 prefix tuning(Li & Liang, 2021)的研究,直接优化提示的过程存在较大的优化难度,训练过程中性能随着可训练参数的变化呈非单调性波动,这表明优化过程不稳定,难以找到最优的提示参数。
在直接优化提示时,需要将部分序列长度用于适配(prefix tokens),这减少了可用于下游任务的序列长度。
作者的方法
神经网络包含许多执行矩阵乘法的密集层,这些层中的权重矩阵通常具有满秩。在适应特定任务时,Aghajanyan 等人(2020)表明预训练语言模型具有低”内在维度”,即使随机投影到较小的子空间仍然可以有效学习。受此启发,我们假设在适应过程中权重的更新也具有低”内在秩”。对于预训练权重矩阵 $W_0 \in \mathbb{R}^{d×k}$,我们通过将其更新表示为低秩分解来约束更新:
其中 $B \in \mathbb{R}^{d×r}$,$A \in \mathbb{R}^{r×k}$,且秩 $r \ll \min(d,k)$。在训练期间,$W_0$ 被冻结且不接收梯度更新,而 $A$ 和 $B$ 包含可训练参数。注意 $W_0$ 和 $\Delta W = BA$ 都与相同的输入相乘,它们各自的输出向量按坐标逐项相加。对于 $h = W_0x$,我们修改后的前向传播产生:
图1
我们在图1 中说明了我们的重参数化,我们对 $A$ 使用随机高斯初始化,对 $B$ 使用零初始化,因此在训练开始时 $\Delta W = BA$ 为零。然后我们将 $\Delta Wx$ 按 $\frac{\alpha}{r}$ 缩放,其中 $\alpha$ 是与 $r$ 相关的常数。当使用 Adam 优化器时,调整 $\alpha$ 与调整学习率的效果大致相同(如果我们适当地缩放初始化),因此,我们简单地将 $\alpha$ 设置为我们尝试的第一个 $r$ 值,而不对其进行调优,这种缩放有助于减少在改变 $r$ 时重新调整超参数的需求(Yang & Hu, 2021)。
全微调的泛化:微调的一种更通用形式允许训练预训练参数的子集,LoRA 更进一步,在适应过程中不要求权重矩阵的累积梯度更新具有满秩。这意味着当将 LoRA 应用于所有权重矩阵并训练所有偏置项时,通过将 LoRA 的秩 $r$ 设置为预训练权重矩阵的秩,我们大致可以恢复完全微调的表达能力。
换句话说,随着我们增加可训练参数的数量,LoRA 的训练大致收敛到原始模型的训练效果,而基于适配器(Adapter)的方法则收敛到 MLP,基于前缀(prefix)的方法则收敛到一个无法处理长输入序列的模型。
Adapters 和 prefix 都无法维持原有架构;而 LoRA 只是增加了 $\Delta W$,可以维持原有架构。
无额外推理延迟:在生产部署时,我们可以显式计算并存储 $W = W_0 + BA$,并像往常一样进行推理。注意 $W_0$ 和 $BA$ 都是 $\mathbb{R}^{d×k}$ 维的,当我们需要切换到另一个下游任务时,我们可以通过减去 $BA$ 然后加上不同的 $B’A’$ 来恢复 $W_0$,这是一个内存开销很小的快速操作,重要的是,这保证了我们在推理时相比微调模型不会引入任何额外的延迟。
在 Transformer 上应用 LoRA
原则上,我们可以将 LoRA 应用到神经网络中任意子集的权重矩阵上,以减少微调时可训练参数的数量。在 Transformer 架构中,自注意力模块有四个权重矩阵 $Wq$、$W_k$、$W_v$、$W_o$,而 MLP 模块有两个,我们将 $W_q$(或 $W_k$ , $W_v$)视为维度为 $d{model} \times d_{model}$ 的单个矩阵(尽管输出维度通常被切分为多个注意力头),为了简单和参数效率,我们的研究仅限于对下游任务适应注意力权重(only adapting the attention weights ),并冻结MLP模块(使其在下游任务中不被训练)。
LoRA 也有其局限性,例如,如果选择将 $A$ 和 $B$ 吸收到 $W$ 中以消除额外的推理延迟,那么在单个前向传递中对具有不同 $A$ 和 $B$ 的不同任务的输入进行批处理就不那么直观。不过,在延迟不那么重要的场景中,可以选择不合并权重,而是动态选择批次中样本要使用的 LoRA 模块。
理解 Low-Rank Updates
我们应该在 Transformer 的哪些权重矩阵上应用 LoRA
在有限的参数预算下,我们应该使用 LoRA 来适应哪些类型的权重以在下游任务上获得最佳性能?我们只考虑自注意力模块中的权重矩阵,我们在 GPT-3 175B 上设置了 18M 的参数预算(在 FP16 下约 35MB ),如果我们适应一种类型的注意力权重,这对应于 $r = 8$,如果适应两种类型,则 $r = 4$,这适用于所有 96 层。结果如表所示:
| 权重类型 | $W_q$ | $W_k$ | $W_v$ | $W_o$ | $W_q, W_k$ | $W_q, W_v$ | $W_q, W_k, W_v, W_o$ |
|---|---|---|---|---|---|---|---|
| 秩 $r$ | 8 | 8 | 8 | 8 | 4 | 4 | 2 |
| WikiSQL ( $±0.5\%$ ) | 70.4 | 70.0 | 73.0 | 73.2 | 71.4 | 73.7 | 73.7 |
| MultiNLI ( $±0.1\%$ ) | 91.0 | 90.8 | 91.0 | 91.3 | 91.3 | 91.3 | 91.7 |
在给定相同可训练参数数量的情况下,对 GPT-3 中不同类型的注意力权重应用 LoRA 后在 WikiSQL 和 MultiNLI 上的验证准确率。同时适应 $W_q$ 和 $W_v$ 总体上给出最佳性能。我们发现对于给定数据集,不同随机种子间的标准差是一致的,我们在第一列中报告了这个值。
注意,将所有调整参数放在 $\Delta W_q$ 或 $\Delta W_k$ 中会导致明显较低的性能,而同时适应 $W_q$ 和 $W_v$ 则产生最佳结果。这表明即使是秩 $r$ 为 4 的矩阵也能在 $\Delta W$ 中捕获足够的信息,因此与使用更大秩的矩阵适应单一类型的权重相比,适应更多的权重矩阵是更好的选择。
LoRA 的最优秩 $r$ 是多少
我们将注意力转向秩 $r$ 对模型性能的影响,我们分别对{ $W_q$, $W_v$ }、{ $W_q$, $W_k$, $W_v$, $W_o$ },以及仅 $W_q$ 进行适应作为比较。
| 权重类型 | $r = 1$ | $r = 2$ | $r = 4$ | $r = 8$ | $r = 64$ |
|---|---|---|---|---|---|
| WikiSQL ( $±0.5\%$ ) | |||||
| $W_q$ | 68.8 | 69.6 | 70.5 | 70.4 | 70.0 |
| $W_q, W_v$ | 73.4 | 73.3 | 73.7 | 73.8 | 73.5 |
| $W_q, W_k, W_v, W_o$ | 74.1 | 73.7 | 74.0 | 74.0 | 73.9 |
| MultiNLI ( $±0.1\%$ ) | |||||
| $W_q$ | 90.7 | 90.9 | 91.1 | 90.7 | 90.7 |
| $W_q, W_v$ | 91.3 | 91.4 | 91.3 | 91.6 | 91.4 |
| $W_q, W_k, W_v, W_o$ | 91.2 | 91.7 | 91.7 | 91.5 | 91.4 |
在不同秩 $r$ 下 WikiSQL 和 MultiNLI 的验证准确率。令人惊讶的是,在这些数据集上,对于同时适应 $W_q$ 和 $W_v$ 来说,即使是秩为 1 也足够了,而单独训练 $W_q$ 则需要更大的 $r$。
表中显示,LoRA 在很小的 $r$ 值下就已经表现得很有竞争力(对于 {$W_q$, $W_v$} 比单独使用 $W_q$ 更明显),这表明更新矩阵 $\Delta W$ 可能具有很小的 “内在秩”。为了进一步支持这一发现,我们检查了不同 $r$ 值选择和不同随机种子所学习到的子空间的重叠程度。我们认为增加 $r$ 并不会覆盖更有意义的子空间,这表明低秩适应矩阵就已经足够了。
实验结果主要说明:
- 即使是很小的秩 ( $r=1$ ),同时适应多个权重矩阵也能获得不错的性能;
- 增加秩 $r$ 并不能显著提升性能,特别是在适应多个权重矩阵的情况下;
- 单独适应 $W_q$ 时需要较大的秩才能达到较好的性能;
这些发现支持了使用低秩适应的有效性,并表明不需要很大的秩就能捕获足够的信息来完成下游任务。
尝试
理解 LoRA
在 LoRA(Low-Rank Adaptation)中,“Low-Rank” 指的是通过低秩近似来调整模型权重,具体来说就是通过引入低秩矩阵来表示对模型原来的矩阵的变化,从而避免了直接调整原模型的大量参数。
低秩
回顾下线代的知识:一个矩阵的 秩(rank)指该矩阵的最大线性无关行(或列)的数量,根据线代的相关知识我们知道,假如一个 $1000 \times 1000$ 的矩阵的秩为 $1$,那就意味着这个矩阵可以用一个 $1000 \times 1$ 的列向量和一个 $1 \times 1000$ 的行向量表示。
对于矩阵 $A$($m \times r$)和矩阵 $B$($r \times n$),其中 $r$ 是矩阵的秩($A$ 和 $B$ 都是满秩,$\text{rank}=r$),由于有定理:
而矩阵 $A$ 和 $B$ 都是满秩时,就有 $\text{rank}(AB) = r$。
更新权重
对于每一层权重 $W$,令其更新后的权重为 $W’$,则可以看做更新就是在原权重的基础上更新了 $\Delta W$,即:
LoRA 的核心思想就是将 $\Delta W$ 表示为两个低秩矩阵 $A$ 和 $B$,即:
其中,矩阵 $A$($r \times k$)和矩阵 $B$($d \times r$),这种分解使得 $AB$ 可以用相对较少的参数来表示更新的 $W$,这就是“低秩”表示的核心思想。另外在初始化时,对 $A$ 使用随机高斯初始化,对 $B$ 使用零初始化,因此在训练开始时 $\Delta W = BA$ 为零。
但是实际使用时并不是直接更新权重,而是分别通过原始权重矩阵 $W$(训练过程中被冻结)和低秩矩阵 $AB$ 计算输出,然后将两者的结果相加:
再加上一个缩放因子:
其中 $\alpha$ 作为一个缩放因子,论文中这样说:
$\alpha$ 是与 $r$ 相关的常数,当使用 Adam 优化器时,调整 $\alpha$ 与调整学习率的效果大致相同(如果我们适当地缩放初始化),因此,我们简单地将 $\alpha$ 设置为我们尝试的第一个 $r$ 值,而不对其进行调优,这种缩放有助于减少在改变 $r$ 时重新调整超参数的需求。
综上,我们需要训练和存储的就是分解出的两个低秩矩阵 $A$ 和 $B$,而 $r \ll d$,因此大量减少了训练的参数与内存的需求。
使用 LoRA
Huggingface 提供的 peft 库是一个常用的工具(官方文档:https://huggingface.co/docs/peft/index),一个简单介绍:
Quickstart
首先 pip install peft;
这里以 Qwen2.5-1.5B 模型为例:
1 | from transformers import AutoModelForCausalLM, AutoTokenizer |
打印结果:
1 | trainable params: 2,179,072 || all params: 1,545,893,376 || trainable%: 0.1410 |
其中我们看:
1 | peft_config = LoraConfig( |
LoraConfig 对 LoRA 微调的一些参数进行设置,其中主要的参数 r 和 alpha 在前面已经讲过,关于 r 值的设置,在原论文中作者认为 2-4 就已经足够,甚至设置为 1 时也能有很好的效果(详细见上述研读部分),关于 target_modules 的设置,论文的实验中也有提到,同时设置 $W_q,W_v$ 或者 $W_q, W_k, W_v, W_o$ 通常会有更好的效果。
然后通过 model = get_peft_model(model, peft_config) 将 LoRA 配置应用到预训练模型中,后面就可以进行训练的步骤了。
训练完成后保存模型可以使用 model.save_pretrained("models/Qwen2_5-1_5B-Instruct-PEFT"),保存后目录结构如下:1
2
3
4models/Qwen2_5-1_5B-Instruct-PEFT
├── README.md
├── adapter_config.json
└── adapter_model.safetensors
后续加载时:
1 | from peft import AutoPeftModelForCausalLM |
LoRA 源码阅读
以下主要来自于:https://martinlwx.github.io/zh-cn/lora-finetuning/,很好的讲解!
查看源码的 LoraModel 类:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32class LoraModel(BaseTuner):
"""
Creates Low Rank Adapter (LoRA) model from a pretrained transformers model.
The method is described in detail in https://arxiv.org/abs/2106.09685.
Args:
model ([`torch.nn.Module`]): The model to be adapted.
config ([`LoraConfig`]): The configuration of the Lora model.
adapter_name (`str`): The name of the adapter, defaults to `"default"`.
low_cpu_mem_usage (`bool`, `optional`, defaults to `False`):
Create empty adapter weights on meta device. Useful to speed up the loading process.
Returns:
`torch.nn.Module`: The Lora model.
Example:
```py
>>> from transformers import AutoModelForSeq2SeqLM
>>> from peft import LoraModel, LoraConfig
>>> config = LoraConfig(
... task_type="SEQ_2_SEQ_LM",
... r=8,
... lora_alpha=32,
... target_modules=["q", "v"],
... lora_dropout=0.01,
... )
>>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
>>> lora_model = LoraModel(model, config, "default")
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import torch
import transformers
from peft import LoraConfig, PeftModel, get_peft_model, prepare_model_for_kbit_training
rank = ...
target_modules = ["q_proj", "k_proj", "v_proj", "out_proj", "fc_in", "fc_out", "wte"]
config = LoraConfig(
r=4, lora_alpha=16, target_modules=target_modules, lora_dropout=0.1, bias="none", task_type="CAUSAL_LM"
)
quantization_config = transformers.BitsAndBytesConfig(load_in_8bit=True)
tokenizer = transformers.AutoTokenizer.from_pretrained(
"kakaobrain/kogpt",
revision="KoGPT6B-ryan1.5b-float16", # or float32 version: revision=KoGPT6B-ryan1.5b
bos_token="[BOS]",
eos_token="[EOS]",
unk_token="[UNK]",
pad_token="[PAD]",
mask_token="[MASK]",
)
model = transformers.GPTJForCausalLM.from_pretrained(
"kakaobrain/kogpt",
revision="KoGPT6B-ryan1.5b-float16", # or float32 version: revision=KoGPT6B-ryan1.5b
pad_token_id=tokenizer.eos_token_id,
use_cache=False,
device_map={"": rank},
torch_dtype=torch.float16,
quantization_config=quantization_config,
)
model = prepare_model_for_kbit_training(model)
lora_model = get_peft_model(model, config)
**Attributes**:
- **model** ([`~transformers.PreTrainedModel`]) -- The model to be adapted.
- **peft_config** ([`LoraConfig`]): The configuration of the Lora model.
"""
1 |
|
Args:
model ([torch.nn.Module]): The model to be adapted.
config ([LoraConfig]): The configuration of the Lora model.
adapter_name (str): The name of the adapter, defaults to "default".
low_cpu_mem_usage (bool, optional, defaults to False):
Create empty adapter weights on meta device. Useful to speed up the loading process.
Returns:
torch.nn.Module: The Lora model.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
其中 `adapter_name` 是适配器的名称,默认值为 `"default"`,同一个模型中可以有多个适配器,通过不同的名称进行区分;
` low_cpu_mem_usage` 判断是否在元设备(meta device)上创建空的适配器权重,设置为 `True` 可以加速模型加载过程,尤其在资源受限的情况下。
注释里也给出了一些序列到序列语言模型和因果语言模型的使用示例:
```python
from transformers import AutoModelForSeq2SeqLM
from peft import LoraModel, LoraConfig
config = LoraConfig(
task_type="SEQ_2_SEQ_LM",
r=8,
lora_alpha=32,
target_modules=["q", "v"],
lora_dropout=0.01,
)
model = AutoModelForSeq2SeqLM.from_pretrained("t5-base")
lora_model = LoraModel(model, config, "default")
1 | import torch |
LoraModel 继承自 BaseTuner ,并且调用了 BaseTuner 的构造函数,我们去查看父类构造函数做了什么:
1 | class BaseTuner(nn.Module, ABC): |
我们主要关注 self.inject_adapter(经简化):
1 | import torch.nn as nn |
接着定位到 self._create_and_replace:
1 | def _create_and_replace( |
接着看 self._create_new_module:
1 |
|
最终我们可以在 layer.py 中找到 LoraLayer 类和 Linear 类
1 | class Linear(nn.Module, LoraLayer): |
我们看 Linear 类的 forward 方法(可以看到 LoRA 前向传播的过程):
1 | def forward(self, x: torch.Tensor, *args: Any, **kwargs: Any) -> torch.Tensor: |
和 LoraLayer 类的 update_layer 方法(可以看到设置 LoRA 的矩阵 $A$ 和 $B$ 的部分,以及设置缩放因子的部分):
1 | def update_layer( |
这些代码也与我们上面梳理的 LoRA 的原理与实现是一样的。