
Understanding from seq2seq to attention
笔记部分内容与图片来自书《深度学习进阶:自然语言处理》——斋藤康毅(好书!😭)
相关论文:https://arxiv.org/abs/1409.0473v7
- 作者认为基本的编码器-解码器模型的一个潜在问题是,神经网络需要能够将源句子的所有必要信息压缩到一个固定长度的向量中,这可能会使神经网络难以处理长句,尤其是那些比训练语料库中的句子更长的句子。
- 为了应对这个问题,作者提出了一种扩展的编码器-解码器模型,该模型学习了如何联合对齐和翻译,每次建议的模型生成一个翻译单词时,它都会在源句子中搜索一组位置,其中包含最相关的信息,然后,该模型根据与这些源位置相关联的上下文向量以及所有先前生成的目标词来预测目标词。
- 解码器在生成每个目标语言词汇时都会计算一个软注意力分布,用于决定哪些源语言词汇应该被关注,这个软注意力分布是通过一个基于RNN隐藏状态( $h$ )和上下文向量(笔记中记作 $c$ )之间的相似度得分的权重函数来计算得到的,最终的目标语言句子由解码器逐步生成。
- 相比于传统的编码-解码模型,该模型的主要改进在于引入了注意力机制(Attention),使得解码器能够更加灵活地选择需要关注的源语言词汇,从而提高了翻译质量。
Tips:论文中的注意力使用加性注意力,而下文笔记中使用的注意力为点积注意力
Seq2Seq 存在的问题与改进
编码器输出的是固定长度的向量,其容易导致信息损失,尤其是处理长序列的时候
编码器
假设我们使用 LSTM 实现一个 Seq2Seq 模型,首先可以看到我们只将编码器中 LSTM 层的最后一个隐藏状态传递给解码器,考虑改进编码器的输出的长度应该根据输入文本的长度相应地改变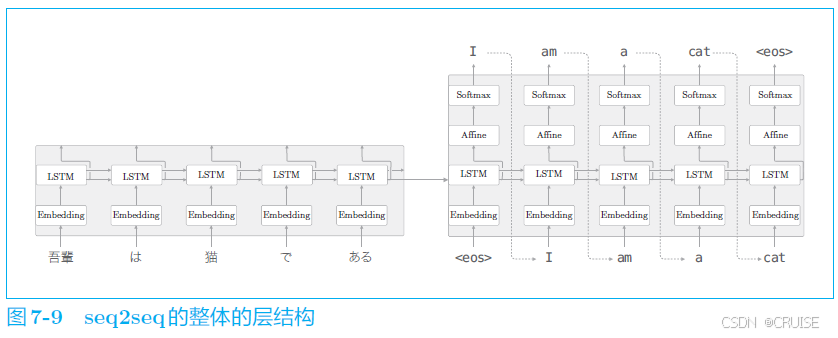
取出各个时刻(token)的隐藏状态向量,就可以获得和输入的单词数相同数量的向量组 $hs$,这样一来,编码器就摆脱了一个固定长度的向量的制约,这是对于编码器方面的改进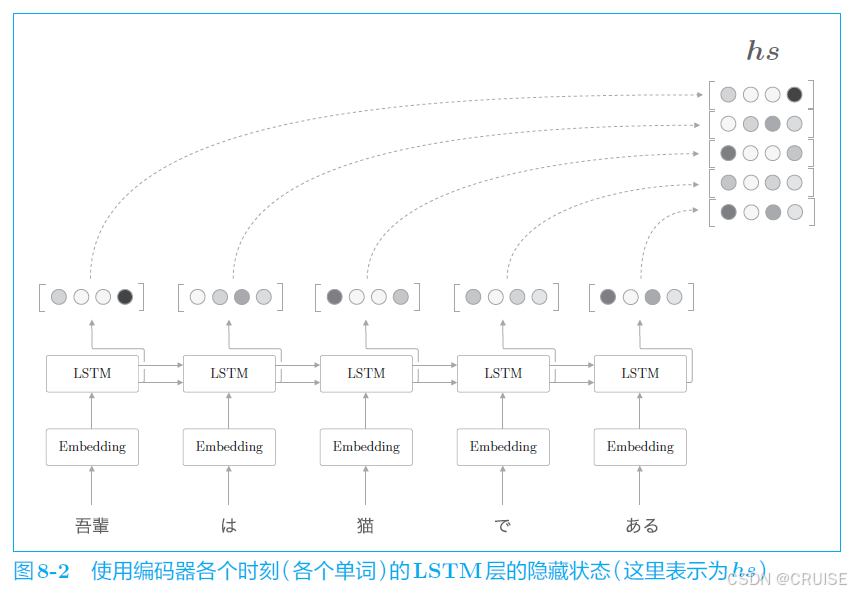
解码器
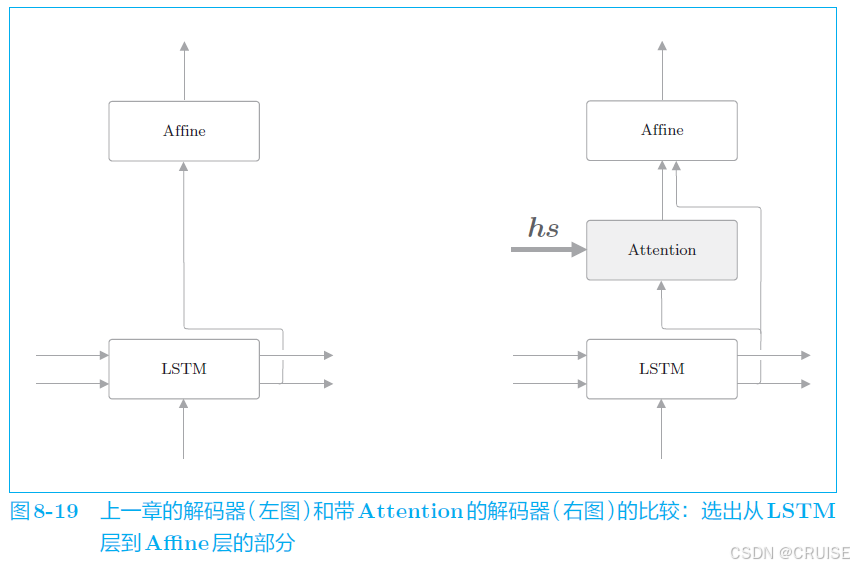
改进前的解码器结构与接受的编码器向量情况,考虑我们如何改进能够用上 $hs$ 里的所有向量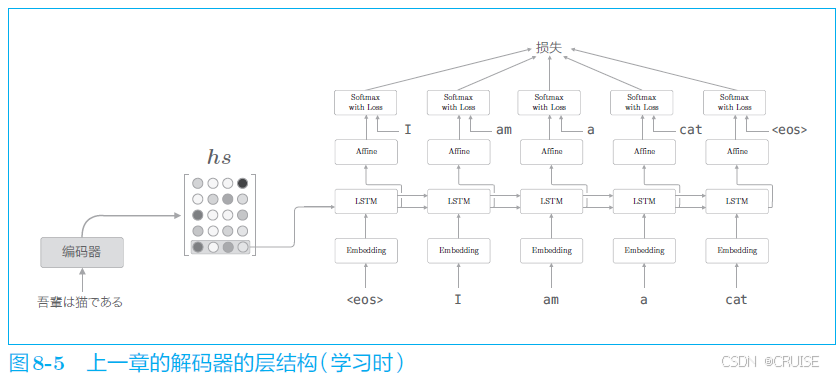
我们进行翻译时,某种程度上可以认为我们是专注于某个单词(或者单词集合),随时对这个单词进行转换的,比如对应到 $猫=cat$,在机器翻译的历史中,很多研究都利用 $猫=cat$ 这样的单词对应关系的知识。这样的表示单词(或者词组)对应关系的信息称为对齐(alignment),我们将要介绍的 Attention 技术成功地将对齐思想自动引入到了 seq2seq 中
那么现在,我们的目标是找出与 “翻译目标词” 有对应关系的 “翻译源词” 的信息,然后利用这个信息进行翻译。也就是说,我们的目标是仅关注必要的信息,并根据该信息进行时序转换。这个机制称为 Attention,是我们要讨论的主题
首先给出改进后的整体结构,我们在 LSTM 层上加了一层 Attention 层,将 $hs$ 的信息传给了 Attention 层与全连接层,接下来看它具体是如何工作的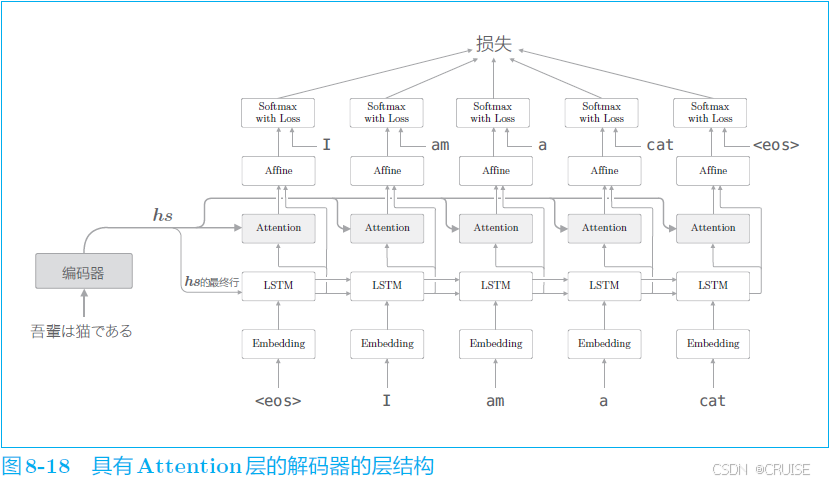
改进后的网络的工作,如前面所说,是要提取单词的对齐信息,具体来说,就是从 $hs$ 中选出与各个时刻解码器输出的单词有对应关系的单词向量,比如解码器输出 $I$ 时,从 $hs$ 中选出表示 $我$ 的对应向量,但是选择这一操作怎么来表示呢,如下图所示
我们通过某种计算获得了表示各个单词重要度的权重 $a$ ,类似于概率分布,各元素是 $0.0$ ~ $1.0$ 的标量,总和是1(可以想到我们后面是需要用到 $softmax$ 的),我们按如下方式计算 $hs$ 中各向量以 $a$ 为权重的加权和,得到上下文向量 $c$ ,如下图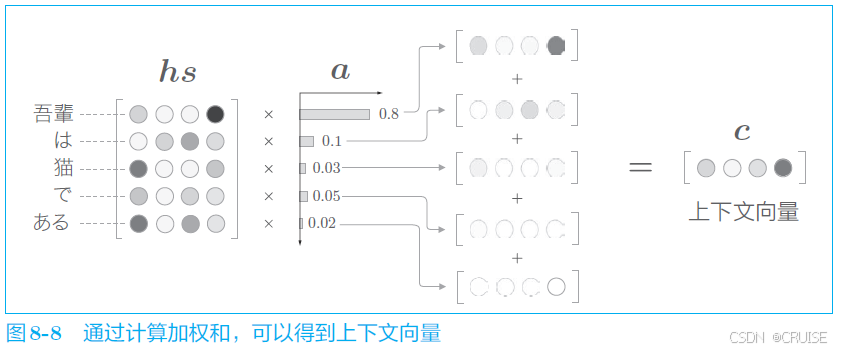
这种加权和一定程度上也代替了我们需要的选择的操作,该操作的简单实现如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import numpy as np
N, H = 5, 4
hs = np.random.randn(N, H)
a = np.array([0.8, 0.1, 0.03, 0.05, 0.02])
ar = a.reshape(5, 1).repeat(4, axis=1)
print(ar.shape)
# (5, 4)
t = hs * ar
print(t.shape)
# (5, 4)
c = np.sum(t, axis=0)
print(c.shape)
# (4,)
# 批处理版
Bs, N, H = 10, 5, 4
hs = np.random.randn(Bs, N, H)
a = np.random.randn(Bs, N)
ar = a.reshape(Bs, N, 1).repeat(H, axis=2)
t = hs * ar
print(t.shape)
# (10, 5, 4)
c = np.sum(t, axis=1)
print(c.shape)
# (10, 4)
进一步深入,考虑我们如何得到各个单词重要度的权重 $a$
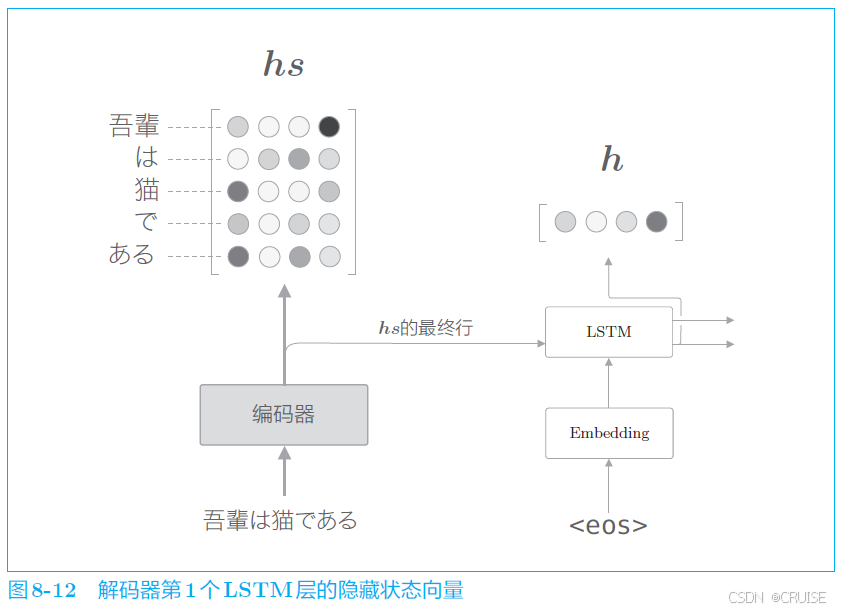
在解码器的 LSTM 层中,每一步都会生成一个隐藏状态向量 $h$,我们的目标是用数值表示这个 $h$ 在多大程度上和 $hs$ 的各个单词向量 相似,一种简单的方式是使用向量内积,即
经过计算我们可以得到图下的结果: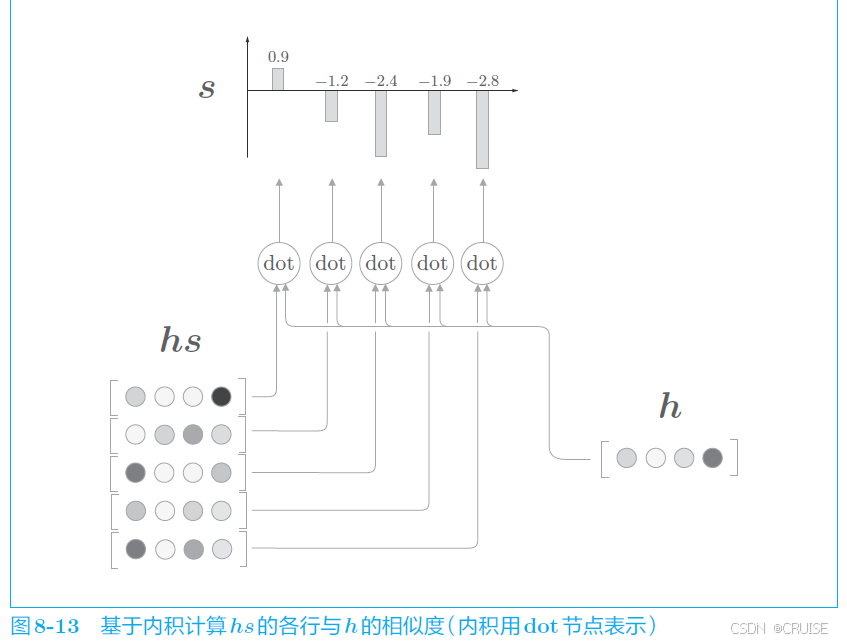
使用 $softmax$ 后: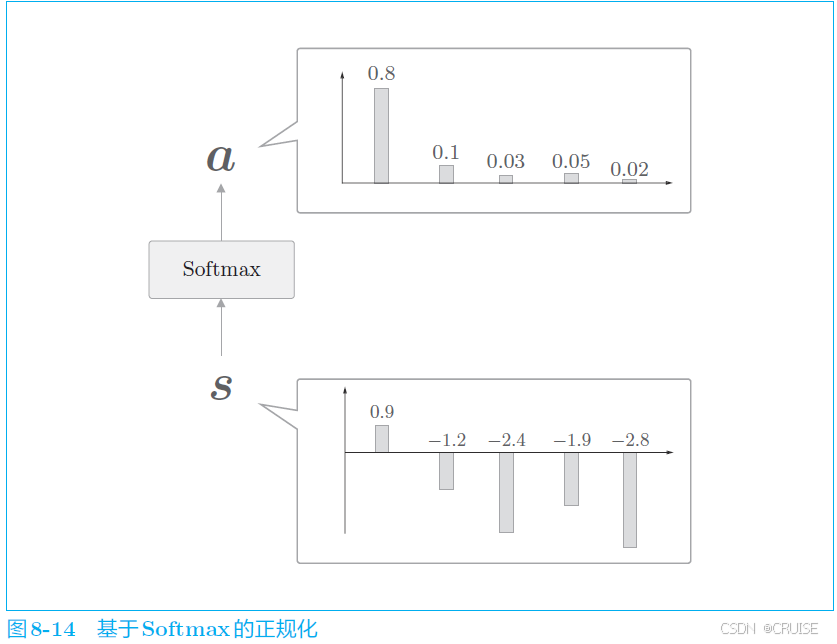
我们使用代码来表示上述过程:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15N, T, H = 10, 5, 4
hs = np.random.randn(N, T, H)
h = np.random.randn(N, H)
hr = h.reshape(N, 1, H).repeat(T, axis=1)
# hr = h.reshape(N, 1, H) # 广播
t = hs * hr
print(t.shape)
# (10, 5, 4)
s = np.sum(t, axis=2)
print(s.shape)
# (10, 5)
a = softmax(s)
print(a.shape)
# (10, 5)
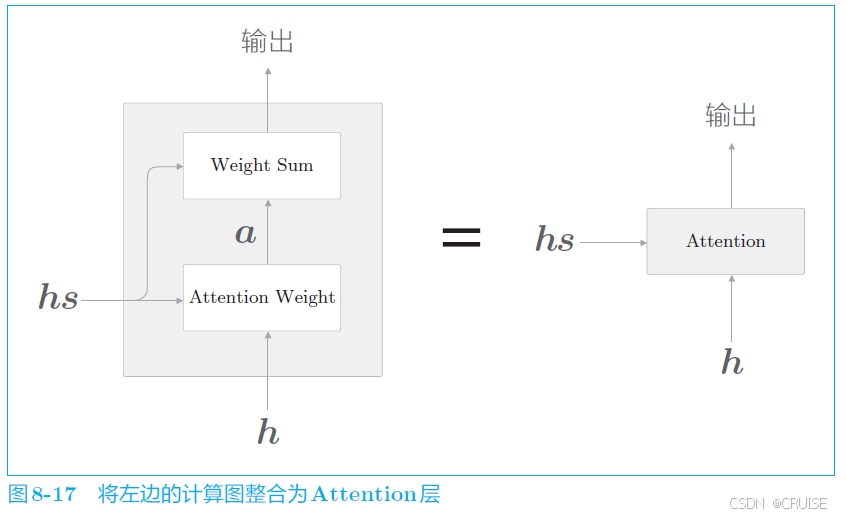
现在我们总结下改进的部分:
- 将 $hs$ 整体作为信息输入解码器,首先我们使用包含了编码器对所有文本的编码信息的 $hs$,用它与解码器的每一个 LSTM 时间步输出的隐藏向量 $h$ 进行计算,得到各个单词重要度的权重 $a$
- 再将其与 $hs$ 的各向量与 $a$ 做加权和,最终得到上下文向量 $c$
- 将其与 $h$ 拼接后一起输入至全连接层,完整过程如下图:
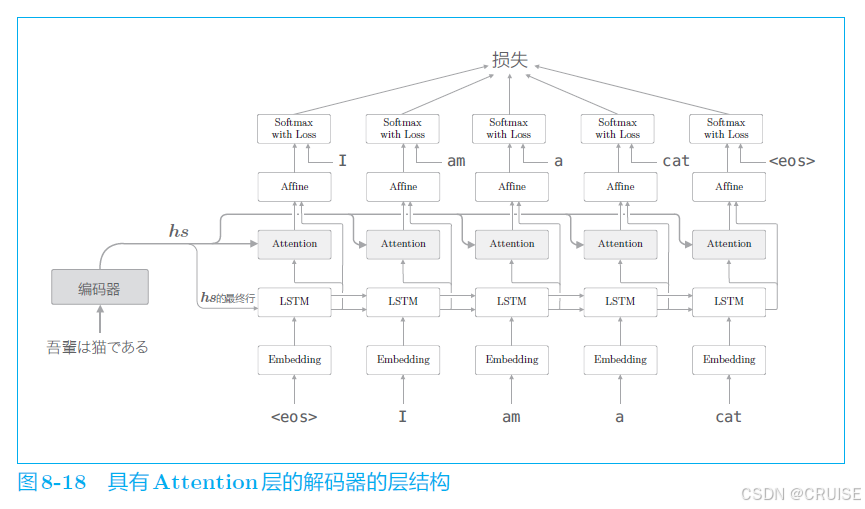
补充:加性注意力计算注意力得分(对齐分数)
- 线性变换:
对编码器输出 $hs$ 和解码器隐藏状态 $h_d$ 进行线性变换:$W(h_i+h_d)$
(假设位置为 $i$)(也可以对二者分别进行线性变换,这里进行简化)
- 特征组合:
$W(h_i+h_d)$
- 激活
$tanhW(h_i+h_d)$
- 投影到标量
使用权重向量 $v$ 将组合后的特征映射到一个标量得分 :
$v^Ttanh(W(h_i+h_d))$
然后经过 $softmax$ 归一化得到注意力权重,并通过加权求和方式得到上下文向量 $c$
代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class Attention(nn.Module): # Additive Attention
def __init__(self, enc_hid_dim, dec_hid_dim):
super(Attention, self).__init__()
self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim) # W
self.v = nn.Linear(dec_hid_dim, 1, bias=False) # v
def forward(self, hidden, encoder_output):
# hidden: [batch, dec_hid_dim], encoder_output: [seq_len, batch, enc_hid_dim * num_directions]
# hidden here is the hidden state of the decoder at the current time step
# encoder_output is the output of the encoder for all time steps
batch_size = encoder_output.shape[1]
seq_len = encoder_output.shape[0]
hidden = hidden.unsqueeze(1).repeat(1, seq_len, 1) # [batch, **seq_len**, dec_hid_dim]
encoder_output = encoder_output.permute(1, 0, 2) # [batch, seq_len, enc_hid_dim * num_directions]
attn_energies = torch.tanh(self.attn(torch.cat((hidden, encoder_output), dim=2))) # [batch, seq_len, dec_hid_dim]
attention = self.v(attn_energies).squeeze(2) # [batch, seq_len]
return torch.softmax(attention, dim=1) # [batch, seq_len]
完整模型:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105# https://arxiv.org/abs/1409.0473v7
import torch.nn as nn
import torch
import random
class Encoder(nn.Module):
def __init__(self, input_dim, embed_dim, enc_hid_dim, dec_hid_dim, dropout):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(input_dim, embed_dim)
self.rnn = nn.GRU(embed_dim, enc_hid_dim, bidirectional=True)
self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
embedded = self.dropout(self.embedding(x))
output, hidden = self.rnn(embedded)
# output: [seq_len, batch, num_directions * hidden_size]
# hidden: [num_layers * num_directions, batch, hidden_size]
hidden = torch.cat((hidden[-2, :, :], hidden[-1, :, :]), dim=1) # [batch, hidden_size * num_directions]
hidden = self.fc(hidden)
hidden = torch.tanh(hidden)
return output, hidden
class Attention(nn.Module): # Additive Attention
def __init__(self, enc_hid_dim, dec_hid_dim):
super(Attention, self).__init__()
self.attn = nn.Linear((enc_hid_dim * 2) + dec_hid_dim, dec_hid_dim)
self.v = nn.Linear(dec_hid_dim, 1, bias=False)
def forward(self, hidden, encoder_output):
# hidden: [batch, dec_hid_dim], encoder_output: [seq_len, batch, enc_hid_dim * num_directions]
# hidden here is the hidden state of the decoder at the current time step
# encoder_output is the output of the encoder for all time steps
batch_size = encoder_output.shape[1]
seq_len = encoder_output.shape[0]
hidden = hidden.unsqueeze(1).repeat(1, seq_len, 1) # [batch, **seq_len**, dec_hid_dim]
encoder_output = encoder_output.permute(1, 0, 2) # [batch, seq_len, enc_hid_dim * num_directions]
attn_energies = torch.tanh(self.attn(torch.cat((hidden, encoder_output), dim=2))) # [batch, seq_len, dec_hid_dim]
attention = self.v(attn_energies).squeeze(2) # [batch, seq_len]
return torch.softmax(attention, dim=1) # [batch, seq_len]
class Decoder(nn.Module):
def __init__(self, vocab_size, embed_dim, enc_hid_dim, dec_hid_dim, dropout, attention):
super(Decoder, self).__init__()
self.vocab_size = vocab_size
self.attention = attention
self.embedding = nn.Embedding(vocab_size, embed_dim)
self.rnn = nn.GRU((enc_hid_dim * 2) + embed_dim, dec_hid_dim)
self.fc = nn.Linear((enc_hid_dim * 2) + dec_hid_dim + embed_dim, vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, input, hidden, encoder_output):
# input: [batch]
# hidden: [batch, dec_hid_dim]
# encoder_output: [seq_len, batch, enc_hid_dim * num_directions]
input = input.unsqueeze(0) # [1, batch]
embedded = self.dropout(self.embedding(input)) # [1, batch, embed_dim]
attn = self.attention(hidden, encoder_output) # [batch, seq_len]
attn = attn.unsqueeze(1) # [batch, 1, seq_len]
encoder_output = encoder_output.permute(1, 0, 2) # [batch, seq_len, enc_hid_dim * num_directions]
weighted = torch.bmm(attn, encoder_output) # [batch, 1, enc_hid_dim * num_directions]
weighted = weighted.permute(1, 0, 2) # [1, batch, enc_hid_dim * num_directions]
rnn_input = torch.cat((embedded, weighted), dim=2) # [1, batch, (enc_hid_dim * 2) + embed_dim]
output, hidden = self.rnn(rnn_input, hidden.unsqueeze(0)) # output: [1, batch, dec_hid_dim], hidden: [1, batch, dec_hid_dim]
embedded = embedded.squeeze(0) # [batch, embed_dim]
output = output.squeeze(0) # [batch, dec_hid_dim]
weighted = weighted.squeeze(0) # [batch, enc_hid_dim * num_directions]
context = torch.cat((output, weighted, embedded), dim=1) # [batch, (enc_hid_dim * 2) + dec_hid_dim + embed_dim]
prediction = self.fc(context) # [batch, output_dim]
return prediction, hidden.squeeze(0), attn.squeeze(1) # prediction: [batch, output_dim], hidden: [batch, dec_hid_dim], a: [batch, seq_len]
class Seq2Seq(nn.Module):
def __init__(self, encoder, decoder, device):
super(Seq2Seq, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.device = device
def forward(self, src, trg, teacher_forcing_ratio=0.5):
# src: [seq_len, batch]
# trg: [seq_len, batch]
batch_size = src.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = self.decoder.vocab_size
output = torch.zeros(trg_len, batch_size, trg_vocab_size).to(self.device)
encoder_output, hidden = self.encoder(src)
input = trg[0, :] # [batch], first input of decoder
for t in range(1, trg_len):
op, hidden, attn = self.decoder(input, hidden, encoder_output)
output[t] = op
teacher_force = random.random() < teacher_forcing_ratio
top1 = op.argmax(1)
input = trg[t] if teacher_force else top1
return output # [trg_len, batch_size, trg_vocab_size]
if __name__ == '__main__':
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = Seq2Seq(Encoder(input_dim=10, embed_dim=25, enc_hid_dim=51, dec_hid_dim=51, dropout=0.5), Decoder(vocab_size=10, embed_dim=25, enc_hid_dim=51, dec_hid_dim=51, dropout=0.5, attention=Attention(enc_hid_dim=51, dec_hid_dim=51)), device).to(device)
src = torch.randint(0, 10, (10, 32)).to(device)
trg = torch.randint(0, 10, (10, 32)).to(device)
output = model(src, trg)
print(output.shape)
print(model)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31Seq2Seq(
(encoder): Encoder(
(embedding): Embedding(10, 25)
Seq2Seq(
(encoder): Encoder(
(embedding): Embedding(10, 25)
(rnn): GRU(25, 51, bidirectional=True)
(fc): Linear(in_features=102, out_features=51, bias=True)
(encoder): Encoder(
(embedding): Embedding(10, 25)
(rnn): GRU(25, 51, bidirectional=True)
(fc): Linear(in_features=102, out_features=51, bias=True)
(dropout): Dropout(p=0.5, inplace=False)
(rnn): GRU(25, 51, bidirectional=True)
(fc): Linear(in_features=102, out_features=51, bias=True)
(dropout): Dropout(p=0.5, inplace=False)
(fc): Linear(in_features=102, out_features=51, bias=True)
(dropout): Dropout(p=0.5, inplace=False)
(dropout): Dropout(p=0.5, inplace=False)
)
(decoder): Decoder(
(attention): Attention(
(attn): Linear(in_features=153, out_features=51, bias=True)
(v): Linear(in_features=51, out_features=1, bias=False)
)
(embedding): Embedding(10, 25)
(rnn): GRU(127, 51)
(fc): Linear(in_features=178, out_features=10, bias=True)
(dropout): Dropout(p=0.5, inplace=False)
)
)
代码参考:https://github.com/bentrevett/pytorch-seq2seq